Lesser Known Facts/Short cuts in Spark(PART2)
This is a second part of Lesser Known Facts/Short cuts in Spark where I will be talking about few of the unknown and some interesting facts about Spark.
Apache Spark itself is vast and it contains 100s of methods to do the same function.
But one thing to note that it doesn't work similar to each other under the hood.
Here the intention of this blog is to make you familiar with the internals of Spark which we might not be aware and how does it work under the hood, plus to give some tips to use them efficiently.
You may find the first part of this blog here.
https://ajithshetty28.medium.com/lesser-known-facts-short-cuts-in-spark-part1-77596e367676
1. Did you know the rdd.cache() is not same as DataFrame.cache()?
We do know that we can store the RDD or Dataframe in memory and Cache is a short hand command for PERSIST.
But the default STORAGE_LEVEL for
rdd.cache() is MEMORY_ONLY
dataframe.cache() is MEMORY_AND_DISK
package org.apache.spark.rdd
package org.apache.spark.sql//dataframe
init.toDF().cache()//dataset
init.cache()
Both uses the same function under the hood.

2. Did you know that the Schema Evolution is possible in PARQUET?
Schema Merging
Like Protocol Buffer, Avro, and Thrift, Parquet also supports schema evolution. Users can start with a simple schema, and gradually add more columns to the schema as needed. In this way, users may end up with multiple Parquet files with different but mutually compatible schemas. The Parquet data source is now able to automatically detect this case and merge schemas of all these files.
Since schema merging is a relatively expensive operation, and is not a necessity in most cases, we turned it off by default starting from 1.5.0. You may enable it by
- setting data source option
mergeSchematotruewhen reading Parquet files (as shown in the examples below), or - setting the global SQL option
spark.sql.parquet.mergeSchematotrue.
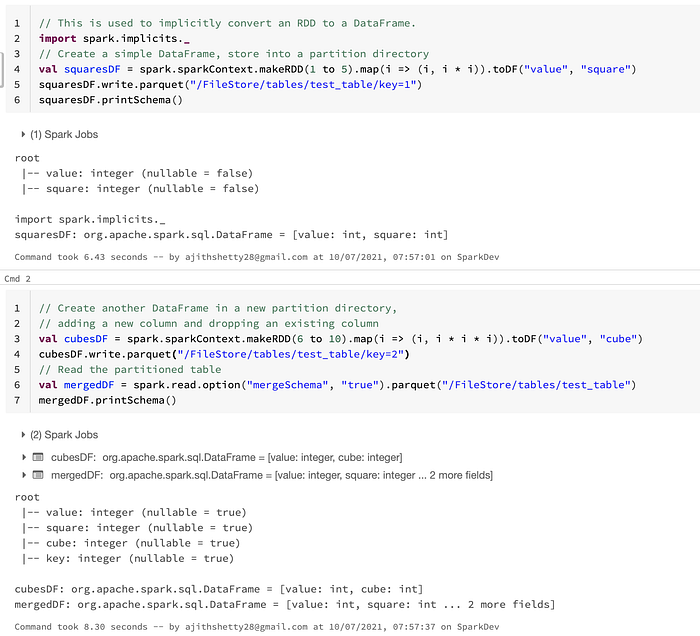
You may find the above notebook in my GITHUB repo. https://github.com/ajithshetty/SparkExamples
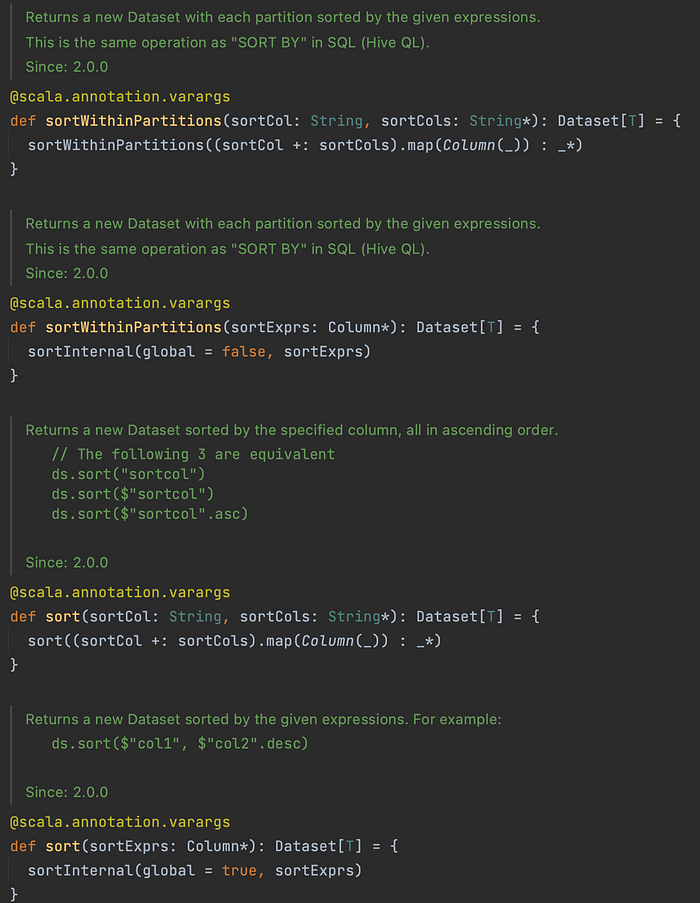
3. Have you heard of Sort Within the Partitions?
SortWithinPartitions is different from SORT.
SortWithinPartition is applied within each of the partitions.
For optimisation purposes, it’s sometimes advisable to sort within each partition before another set of transformations. You can use the sortWithinPartitions method to do this.
sortWithinPartition is similar to SORT BY in HIVE.
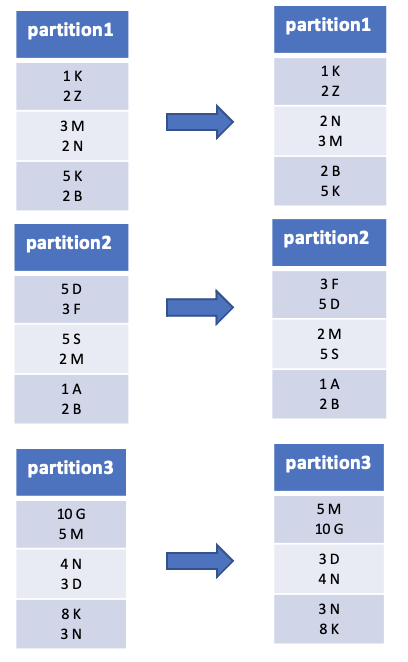
4. Some internals on Coalesce And Repartition
Coalesce Can only take an Integer as an argument.

Coalesce is used to decrease the number of Partitions. And when we try to increase the number of partition, it will stay at the current number of partitions.
Coalesce is a short hand command or Repartition but with SHUFFLE property set to FALSE.
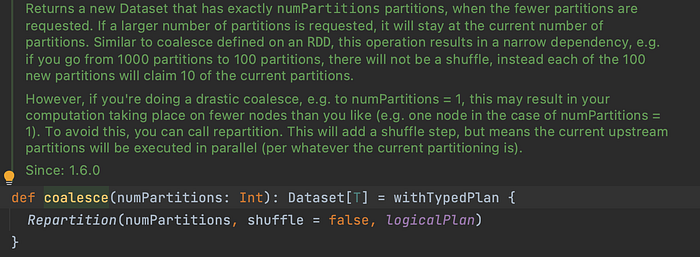
In case of Repartition we can give the number of partitions and as well as the Column name by which the reparation should occur.

Repartition by Column uses the spark.sql.shuffle.partitions(default 200).
This is similar to DISTRIBUTE BY in HIVE.

5. Spark SQL built in cache for Metadata
Spark SQL caches Parquet metadata for better performance. When Hive metastore Parquet table conversion is enabled, metadata of those converted tables are also cached. If these tables are updated by Hive or other external tools, you need to refresh them manually to ensure consistent metadata.
// spark is an existing SparkSession spark.catalog.refreshTable("my_table")
Will be continued……………………

I hope you liked this blog. Feel free to put a comment in here if you have any suggestions or feedback for me, or reach out to me in LinkedIn.
Ajith Shetty
BigData Engineer — Love for Bigdata, Analytics, Cloud and Infrastructure.
Subscribe✉️ ||More blogs📝||Linked In📊||Profile Page📚||Git Repo👓
Subscribe to my: Weekly Newsletter Just Enough Data
