Hey there, I’m using Mage!

How far have we reached already. The Data engineering is in boom and the Big Data tools are growing ever since.
Every day new Tools are introduced and the current tools are adding new features to support all the new use cases we are encountering in the 2022 and beyond.
If you look at a blog from LakeFS, the tools and technologies in each stage of the data are increased rapidly and you will find a different ways to tackle your problems based on your use case.

What do we need when we need to develop a new Data Pipeline.
Without complicating let’s talk in a layman’s term.
We need to see from where we can pull the data from.
We need to see how we can transform the data.
After the transformation you might need to write the data and share with the business.
There are many more steps other than these.
But now comes how are we going to take care of orchestration all these steps and and run them sequentially or parallel.
Mage
Mage is an Open source data pipeline tool for transforming and integrating data.
Using mage You can Integrate and synchronize data from 3rd party sources
Build real-time and batch pipelines to transform data using Python, SQL, and R
Run, monitor, and orchestrate thousands of pipelines without losing sleep.
Source: mage.ai
Why Mage
Mage gives you the power to transform and integrate the data and you can orchestrate them.

Mage is preloaded with the default blocks with which you can interact with the data.

You can run your pipeline in production environments with the orchestration tools
Mage gives you the flexibilty to write your own business logic in the notebooks and you can visualise the same with the prebuilt charts,
Fundamental concepts of Mage
Project
Is a repository where the code for your pipelines are stored.

Pipelines
Pipelines are the reference to the blocks of code you want to run.
Blocks
Block is a a file with the code which is going to define what do you want the run.
Using Data Loader we can connect to

Transform gives you the processes to transform your data like aggregation, fill in missing values etc.
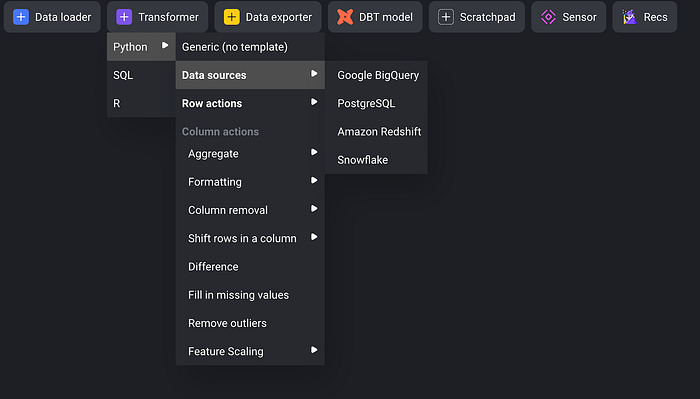
Data Exporter is to export the data to given location.
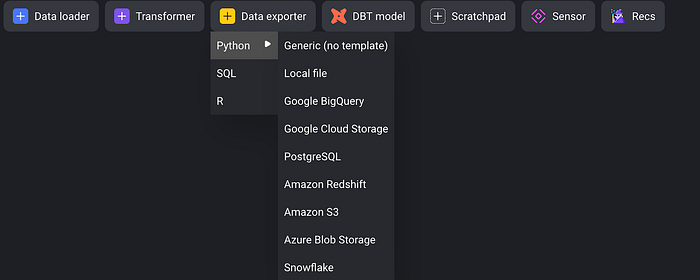
Using mage you can connect to any popular databases like Amazon redhsfit, S3, BigQuery Snowflake etc.
You can write Python code, SQL commands or R based on your business use cases.
Connect to DBT.
And you can create the sensor rules to run the jobs.
Data Products
Are the putput of each and every block. And each data product produced by a block can be automatically partitioned, versioned, and backfilled.
Triggers
Trigger is an instrcution how do you wnat your pipeline to run.
- Shedule: based on the date and time
- Event: based on an event when it occurs.
- Api: calling the pipeline from an API
Run
Triggering the pileline, either a block or the entire pipeline
Log
Is where you can check for any failues or the output information.
And many more which are Work In Progress state.
DEMO
Lets use the docker to run the mage in local.
docker run -it -p 6789:6789 -v $(pwd):/home/src mageai/mageai \
mage start demo_project
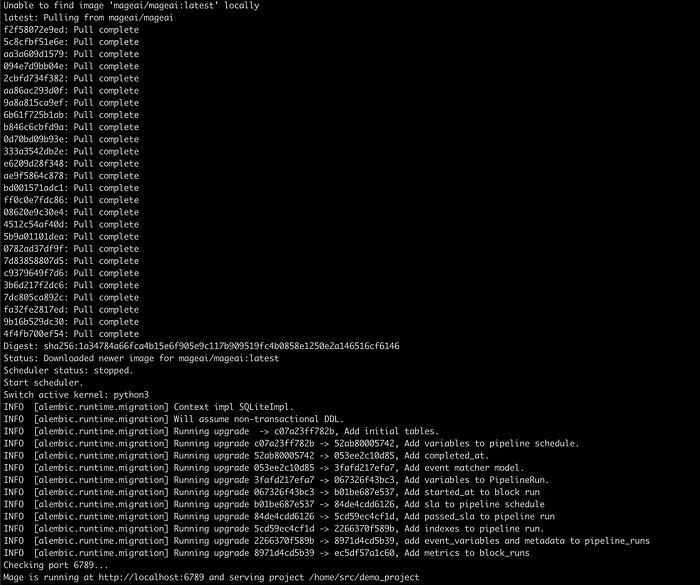
Hit the url http://localhost:6789/

So there is a pre-created pipeline already.
What’s the fun in that. Let’s create a new pipeline and see how easy it is to apply all type of transformations.
For our use case let’s download a Taxi data.
Taxi data is in local. Let’s upload to AWS s3.
The use case:
- Connect to S3 to access Taxi data.
- Taxi data has unwanted columns, select only Location ID and zone.
- Remove the duplicate zones.
- Remove duplicate records for Location ID and zone.
- Write the final data to s3 with timestamp prepended with the file name.
Execution:
Update the io_config.yaml file and add the AWS_ACCESS_KEY and AWS_SECRET_ACCESS_KEY to access aws.
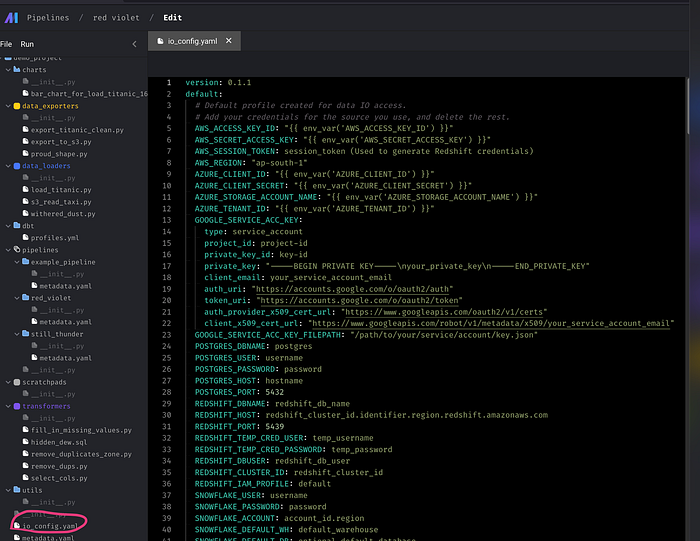
Click on Data Loader and select Amazon S3.

The code is fully ready and is at your disposal.
Update the bucket name and the object key where your file is stored.
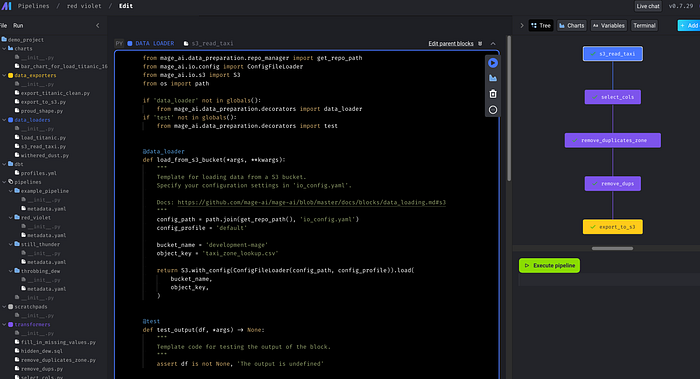
Lets see how the data looks like. Click on Run Icon.
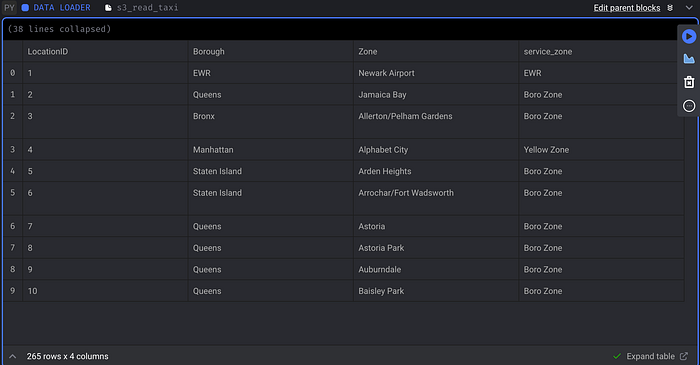
Let’s try to visualize the data.
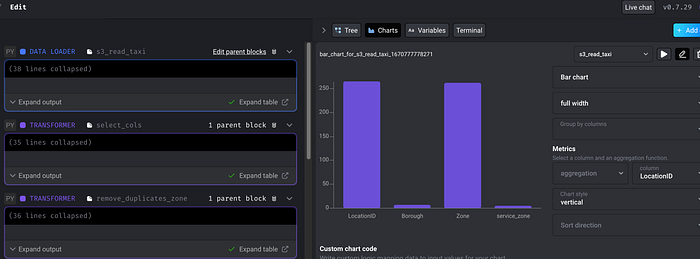
Okay now lets create a transformation to select only location_id and zone.
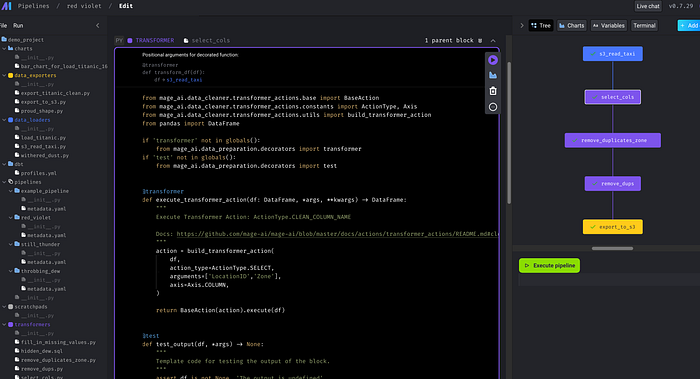
Under Transformer >> Python >> column removal >> keep columns.
Update the arguments in the code.
Now to Transformer >> python >> fill in missing values.
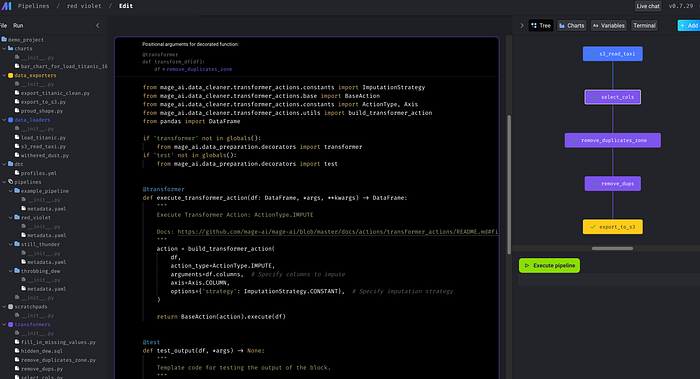
Select Data exporter >> Amazon s3
Update the Object key to prepend the timestamp.
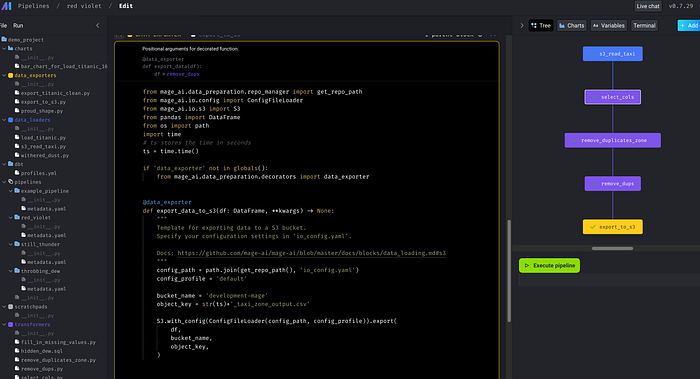
Now you can run each of the blocks to make sure they are running without any issue.
Finally lets create a Trigger
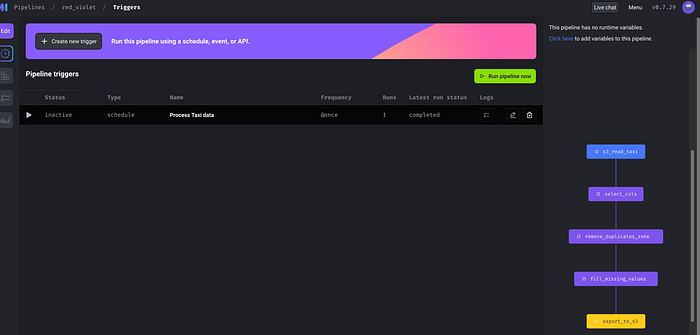
Lets run and look for any error in the logs.
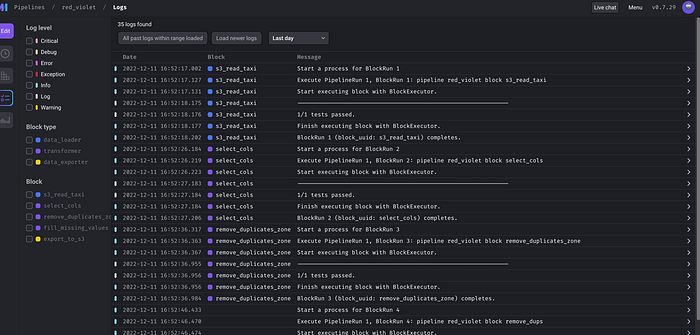
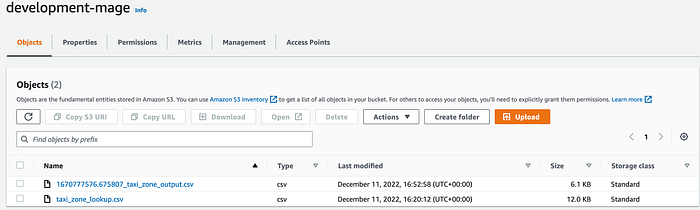
Let’s make sure we have the final data in S3.
So frankly it takes less than 5 minutes to create a new pipeline with very minimal experience in the Mage.
It is easier to define your use case in the Mage. You can use the pre built blocks and add your custom configurations.
To make sure that it is correct, you can trigger individual blocks and see the output as you code. Plus you can visualize.
Once the pipeline is created, in one click you can create a trigger schedule.
And Monitoring plus logs are easily accessible to debug for any issues.
Final Thought
Mage is much more than what we have discussed in this blog. And we wouldnt be able to cover all the cool features.
Here we have mainly concentrated on what is Mage and how is it going to be helpful for the data engineers.
I would strongly recommend you to go through the below references. The Mage team has written all the cool things in the documentation.
References:

Ajith Shetty
Bigdata Engineer — Bigdata, Analytics, Cloud and Infrastructure.
Subscribe✉️ ||More blogs📝||LinkedIn📊||Profile Page📚||Git Repo👓
