DEEQU, I mean Data Quality
We say how we can turn the world upside down with the power of DATA. And it is rightly so.
But a small mistake in the data could send the same world for a toss.
A comma in an Amount column would make a lot of difference.
Data quality is something which you can never ignore and it should always be a part of your pipeline FOR THE LIFETIME.
At this moment of time, the use of Spark is enormous. No pipeline would be complete without having Spark in between.
We need a framework which can talk to Spark directly and it can run run on top of Big data.
Enter, Amazon Deequ.
Introduction
Deequ is a library built on top of Apache Spark for defining “unit tests for data”, which measure data quality in large datasets.
Python users may also be interested in PyDeequ, a Python interface for Deequ. You can find PyDeequ on GitHub, readthedocs, and PyPI.
What does it do
Amazon Deequ would help you in:
- Metrics Computation: You can use Deequ to get the quality metrics like maximum, minimum, correlation, completeness etc. Once the metrics are calculated you can store the data in S3 to analyse at later point.
- Constraint Verification: You may define the constraint verification and the Deequ will generates the data quality report.
- Constraint Suggestion: Well Deequ is smart enough to generate automated constraints based on the data you define.

Deequ reads the data directly and runs the Constraints verification directly on top of the Spark and generates the Data Quality report.
User can provide the constraints to verify or the Deequ could suggest it for you.
Once the Metrics or report is generated, the output could be saved in a local file or S3, which can be queried at later point.
Supported list of Analyser

How does it help
- Using Deequ, you can create a pipeline to validate the completeness or the missing of your data.
- You can provide the constraints to verify or let the Deequ define it for you.
- You can use Deequ for Anomaly detection.
- Deequ supports the Repository where you can store your metrics results and query later.
- Deequ can profile all your columns.
Demo
Setup:
We will be using Databricks community edition for easy setup and demo.
https://community.cloud.databricks.com/
- install the library.
2. Import the Classes
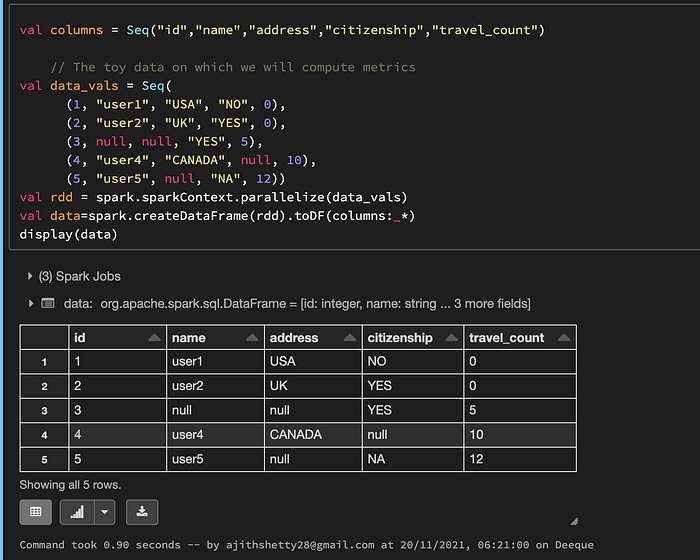
3. Setup the Dummy Data

4. Lets create the repository in the local file system.
It can be S3 location as well.
We need to pass the tag, which under which each of your run metrics will be stored.

5. Lets create the Verification Suite.
Where we define all the checks we want to perform.
In our example, we want to check:
a. Completeness on id and name
b. Record count should be greater than 5.
c. citizenship should be either YES or NO
d. The travel_count should not be negative.

And here you can see the result.
Our check has failed for:
- record count, We expected it to be greater than 5.
- name column contains null
- citizenship, contains a value other than YES and NO
Checks have succeeded for:
- travel count which is not lesser than 0 for any records
- ID column never being null.
Now let’s save the data and query it.

Give the useRepository method and pass the repository Name.
Now either you can query on top of repository for a given column.
Or you can convert the data to Dataframe.

Bonus: You can run the profiling for all the columns by just 1 command.

You may find the above code example here:
Reference:

Ajith Shetty
Bigdata Engineer — Bigdata, Analytics, Cloud and Infrastructure.
Subscribe✉️ ||More blogs📝||LinkedIn📊||Profile Page📚||Git Repo👓
Interested in getting the weekly newsletter on the big data analytics around the world, do subscribe to my: Weekly Newsletter Just Enough Data
